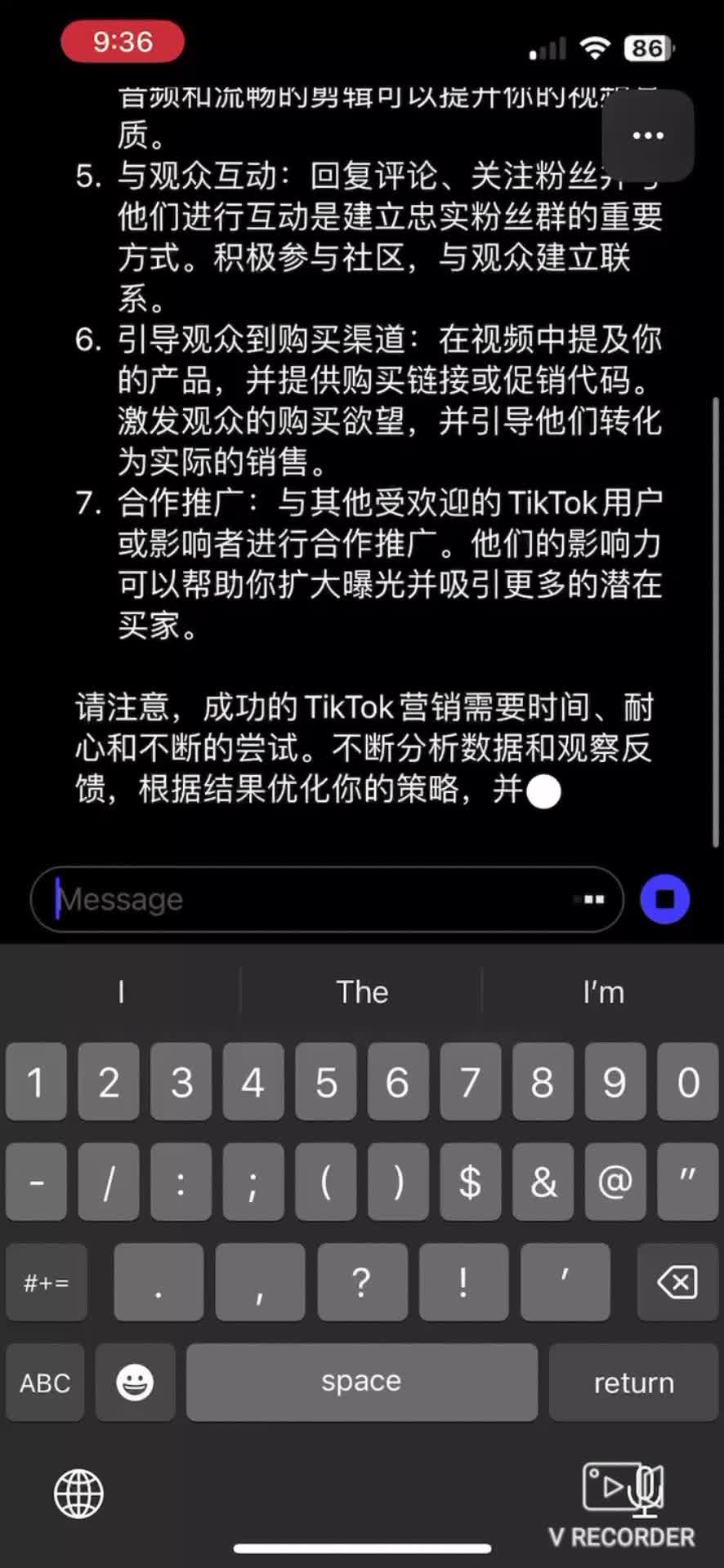
ChatGPT 基于 GPT-3.5 模型微調(diào)而成,以語言服務模型 InstructGPT 為基礎(chǔ),通過人類回饋增強學習訓練模型 RLHF,不過數(shù)據(jù)設(shè)置略有不同。它以對話方式進行交互,既能夠做到回答問題,也能承認錯誤、質(zhì)疑不正確的前提以及拒絕不恰當?shù)恼埱螅芤愿N近一般人的對話方式與使用者互動。
有了GPT-3.5的加持,ChatGPT經(jīng)訓練后提升了對答如流的能力。GPT-3只預測任何給定的單詞串之后的文本,而ChatGPT則試圖以一種更像人類的方式與用戶發(fā)生互動。ChatGPT的互動通常是非常流暢的,并且有能力參與各種主題,與幾年前才面世的聊天機器人相比,顯示出了巨大的改進。
OpenAI官方稱,ChatGPT是在人類的幫助下創(chuàng)建并訓練的,人類訓練師對該AI早期版本回答查詢的方式進行排名和評級。然后,這些信息被反饋到系統(tǒng)中,系統(tǒng)會根據(jù)訓練師的偏好來調(diào)整答案——這是一種訓練人工智能的標準方法,被稱為強化學習。



























































































 免費參與·100+跨境活動
免費參與·100+跨境活動 
 免費下載·4000+跨境資料
免費下載·4000+跨境資料 
 免費學習·2000+直播課程
免費學習·2000+直播課程 
 免費加入·15萬+賣家交流群
免費加入·15萬+賣家交流群