

























































































 免費參與·100+跨境活動
免費參與·100+跨境活動 
 免費下載·4000+跨境資料
免費下載·4000+跨境資料 
 免費學習·2000+直播課程
免費學習·2000+直播課程 
 免費加入·15萬+賣家交流群
免費加入·15萬+賣家交流群 


2020-04-17 09:37

Keen
讀完需要
6分鐘
速讀僅需 2分鐘
你有沒有遇到過這樣的問題,網頁里面有幾百個網址鏈接,需要你統計下來,你會一一粘貼復制到表格里嗎?
或者要統計公司潛在客戶的郵箱,需要通過關鍵詞去搜索,然后每個網頁都要點擊進去,找找看有沒有郵箱呢?
對于上面這張種大批量重復的工作,難道就沒有更好的、快捷的、簡單的解決方案嗎?
當然是有的,今天這篇文章將給你分享 ——如何利用簡單爬蟲解決重復大量的工作。
不過,在進入教程之前,我們要聊聊:
什么是爬蟲
簡單來說,爬蟲就是一種網絡機器人,主要作用就是搜集網絡數據,我們熟知的谷歌和百度等搜索引擎就是通過爬蟲搜集網站的數據,根據這些數據對網站進行排序。
既然谷歌可以利用爬蟲搜集網站數據,那我們是否能利用爬蟲幫我們搜集數據呢?
當然是可以的。
我們可以用爬蟲做什么
前面已經講過,如果你遇到一些重復大量的工作,其實都可以交給爬蟲來做,比如:
?搜集特定關鍵詞下的用戶郵箱?批量搜集關鍵詞?批量下載圖片?批量導出導入文章?……
比如我想搜索iphone case的相關用戶郵箱,那么可以去Google搜索iphone case這個關鍵詞,然后統計下相關網頁,把網址提交給爬蟲程序,接著我們就等著出結果就行了。
當然,創作一個特定的爬蟲程序需要一定的技術基礎,市面上主流都是使用python來制作爬蟲程序,不過我們今天用一個更簡單易懂的爬蟲軟件——Google Sheet,不用寫任何代碼的哦!
利用Google Sheet爬取數據
Google sheet(以下簡稱GS)是Google旗下的在線辦公套件之一,和微軟的辦公三劍客正好一一對應:
?Google doc - Word?Google sheet - Excel?Google presentation - PPT
基本上Excel上的公式都可以在GS上運行,不過GS還要另外一個公式,是Excel不具備的,也就是
IMPORTXML
我們新建一個GS,這個操作和Execl操作一致,然后在A1欄輸入我們需要爬取數據的網址,記得網址必須包含https或http,只有這種完整寫法才會生效。
然后在B1欄輸入
=importxml(A1,''//title")
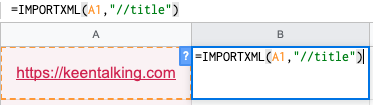
在B1欄輸入完成之后我們就會得到如下數據
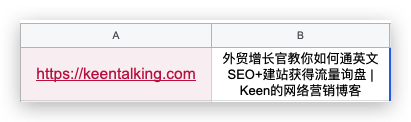
這樣就獲得了網址的SEO Title。
SEO Title出現在每個瀏覽器窗口的標簽處,也是網站呈現給Google搜索引擎的第一登陸點,里面包含該網頁的關鍵詞等重要信息。
接下來我們在C1欄輸入如下公式:
=IMPORTXML(A1,"http://meta[@name='description']/@content")
然后我們就獲得了網頁的Meta Description

我們能看到,剛才搜集的兩個信息就是Google SERPs中很重要的兩個元素,Title和Description,基本上要做好站內SEO,這兩點要做好。
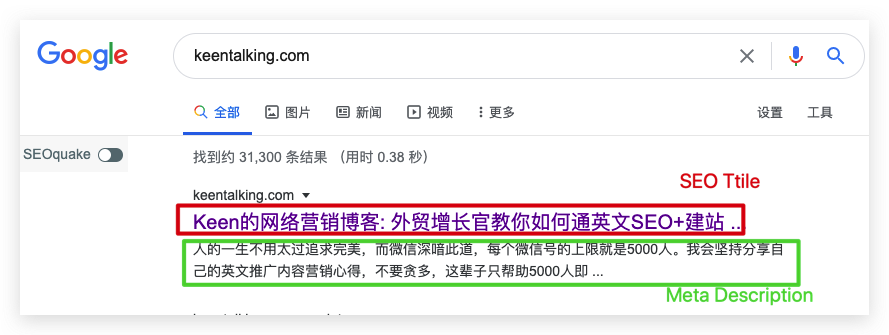
批量爬取網頁SEO信息
按照上面的兩個公式,我們分別在A1B1C1欄中輸入網址、Title、Description,然后A列填滿想要爬取的網址,B列和C列利用Excel的復制下拉選項,就是鼠標放到C1欄的右下角出現十字標識后,往下拉動鼠標,C列的其他欄會自動填充好C1的公式:
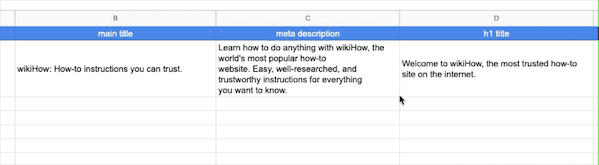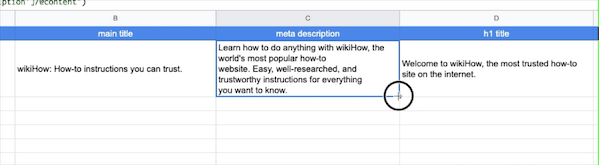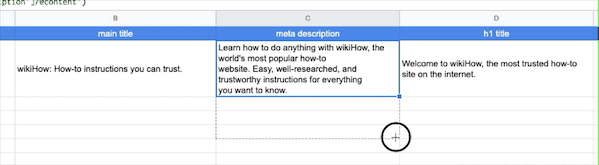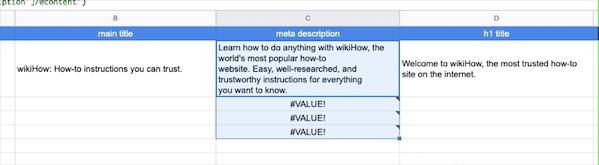
然后我們就得到了所有網址的Title和Description
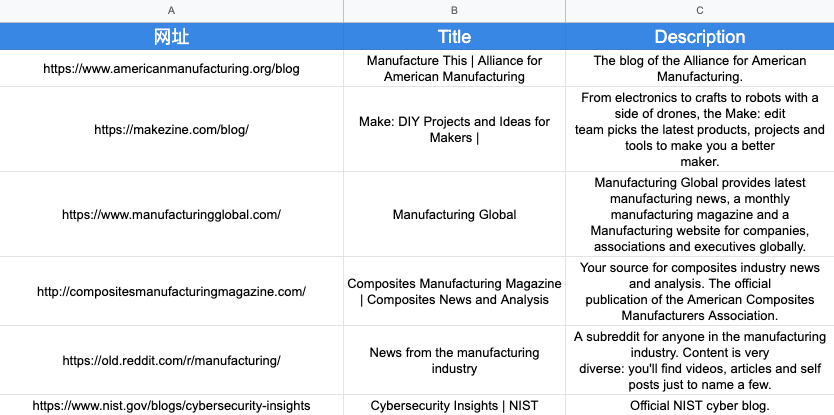
統計完這些數據之后,我們之后就再也不用愁怎么寫SEO Title啦。
如果大家想爬取整個網址的Title與Description,可以把競品的網址全部放上來。至于如何獲取整個網址的鏈接,大家可以去查一下網址的sitemap.xml,在這里面可以找到一個網站所有的鏈接。
了解公式結構
既然importxml可以批量爬取SEO Title,那么當然也是可以爬取其他內容的,比如郵箱地址與鏈接地址,我們先來分析一下公式結構:
=IMPORTXML(A1,"default")
A1表示所在列,default表示需要爬取的頁面內容結構,所以我們只要修改default值,就能夠爬取更多信息,這里給大家展示一下我們在做SEO和統計信息中常用的值
站內鏈接,其中的domain.com換成要統計的域名
//a[contains(@href, 'domain.com')]/@href
站外鏈接,其中的domain.com換成要統計的域名
//a[not(contains(@href, 'domain.com'))]/@href
郵箱統計:
//a[contains(@href, 'mailTo:') or contains(@href, 'mailto:')]/@href
社交鏈接,包括linkedin, fb, twitter
//a[contains(@href, 'linkedin.com/in') or contains(@href, 'twitter.com/') or contains(@href, 'facebook.com/')]/@href
如果你想了解更多能使用的爬蟲公式,可以參考Google 官方文檔
https://support.google.com/docs/answer/3093342?hl=zh-Hans
也可以深入了解一下xpath
https://www.w3schools.com/xml/xpath_intro.asp
(來源:外貿增長官)
以上內容屬作者個人觀點,不代表雨果網立場!本文經原作者授權轉載,轉載需經原作者授權同意。






























