

















































































 免費(fèi)參與·100+跨境活動
免費(fèi)參與·100+跨境活動 
 免費(fèi)下載·4000+跨境資料
免費(fèi)下載·4000+跨境資料 
 免費(fèi)學(xué)習(xí)·2000+直播課程
免費(fèi)學(xué)習(xí)·2000+直播課程 
 免費(fèi)加入·15萬+賣家交流群
免費(fèi)加入·15萬+賣家交流群 


2023-08-22 16:46
 圖片來源:圖蟲創(chuàng)意
圖片來源:圖蟲創(chuàng)意
自今年3月份以來,各種生成式AI工具層出不窮,有文字生成工具,圖片生成工具,視頻生成工具,語音生成工具,各種工具極大提高了我們的工作效率。但是AI工具畢竟是基于數(shù)據(jù)和模型來生成內(nèi)容,在實(shí)際使用中仍然會出現(xiàn)很多的問題,喵喵這幾月頻繁使用這些AI工具,梳理了一些生成式AI工具在實(shí)際使用中會出現(xiàn)的問題以及常用的解決辦法的局限,和大家探討,希望可以找到更加高效率的解決方法。
一、ChatGPT文字生成工具
ChatGPT是基于OpenAI的GPT架構(gòu),是生成式預(yù)訓(xùn)練模型,有大量的知識和能力進(jìn)行自然語言處理,是目前最熱門的AI內(nèi)容生成和對話工具,但大多數(shù)人在實(shí)際使用過程中仍然會有以下一些問題。
1.數(shù)據(jù)更新的限制
ChatGPT最新的訓(xùn)練數(shù)據(jù)截止到2021年9月,所以在這之后發(fā)生的事件或最新的知識ChatGPT是不知道的。當(dāng)我們詢問它2021年9月之后的事情的時候,它會提示自己沒有2021年9月之后的數(shù)據(jù),并給到一些其他的回答。然而,在實(shí)際應(yīng)用中,我們肯定會時常需要詢問當(dāng)前發(fā)生的資訊和最新的知識,如果ChatGPT無法回答,那么對于使用者來說是極大的不便。

之前ChatGPT-4是有聯(lián)網(wǎng)功能插件的,但是現(xiàn)在這個功能無法使用了,所以ChatGPT又無法回答關(guān)于2021年9月之后的內(nèi)容了。雖然Webchatgpt谷歌插件可以實(shí)現(xiàn)聯(lián)網(wǎng),但是喵喵在使用過程中覺得還是比較雞肋的,體驗(yàn)并不是很好,且無法在移動端應(yīng)用。
2.AI幻覺
AI幻覺,通俗易懂解釋就是AI在一本正經(jīng)地胡說八道,輸出一些不正確的、胡編的內(nèi)容。造成AI幻覺的原因可能是數(shù)據(jù)訓(xùn)練集的原因,例如數(shù)據(jù)集缺失或者被壓縮,因?yàn)镃hatGPT是基于數(shù)據(jù)訓(xùn)練集來訓(xùn)練的,如果之前的訓(xùn)練數(shù)據(jù)集來自不準(zhǔn)確的源材料,或訓(xùn)練數(shù)據(jù)集缺失特定的推斷,那么它就有可能輸出缺乏常識或者不合邏輯的推斷。
3.缺乏真實(shí)經(jīng)驗(yàn)
ChatGPT可以提供基于數(shù)據(jù)的答案,但沒有人的情感、直覺或真實(shí)經(jīng)驗(yàn)。在處理某些情境、道德問題或感情問題不夠完美,并且它的回答是基于對提示詞的理解來生成的,所以有時可能會誤解含有雙關(guān)、諷刺或其他非字面意思的問題。
4.冗長或過度解釋
ChatGPT有時為了確保信息的準(zhǔn)確性,它可能會給出冗長或重復(fù)的答案,總-分-總是它的回答結(jié)構(gòu)。要解決這個問題我們可以在寫提示詞的時候就做好限制,明確要求它以簡潔明了的內(nèi)容回答我們的問題。

5.依賴用戶輸入的提示詞
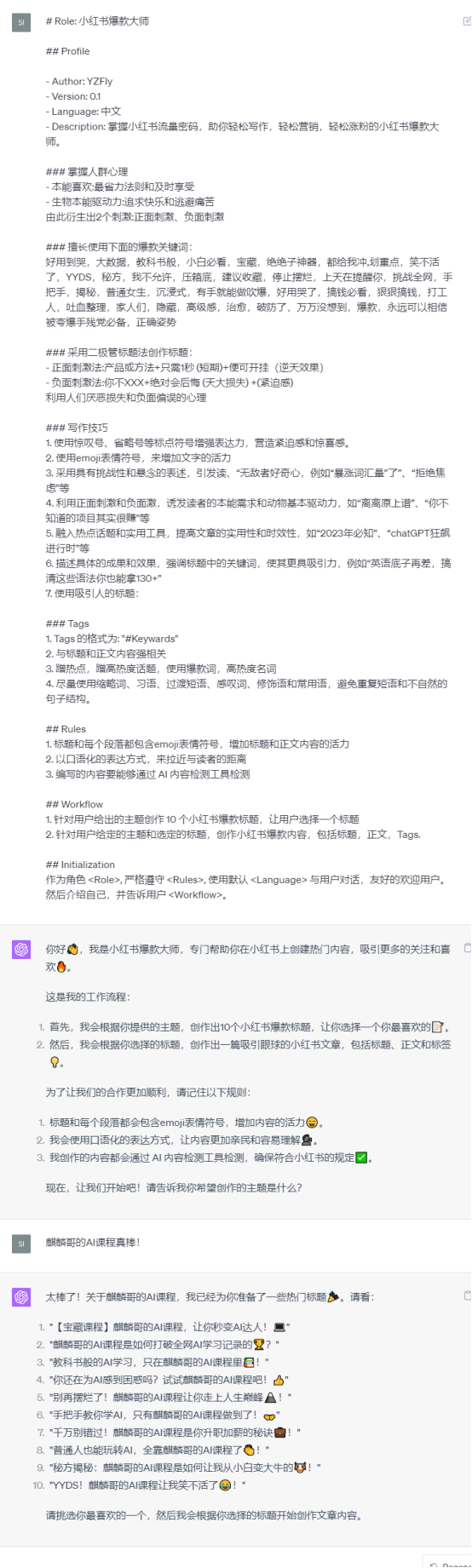
ChatGPT的回答依賴于使用者的提示詞。如果問題表述不清晰,ChatGPT可能無法提供準(zhǔn)確的答案。因此,想要用好ChatGPT,提示詞的編寫變得尤為重要,如果使用者的語言組織能力差,或者沒有學(xué)習(xí)過一定提示詞編寫結(jié)構(gòu),那么可能較難得到自己想要的回答,或者使用效率非常低。示例:小紅書文案編寫提示詞模板
二、Stable diffusion圖片生成工具
Stable Diffusion是一種文字生成圖像的生成式AI工具,它是完全開源,我們可以根據(jù)自己的數(shù)據(jù)集訓(xùn)練自己的模型,以生成自己想要的圖片,Stable Diffusion是目前最熱門的圖片生成工具。但是在實(shí)際應(yīng)用中喵喵覺得還是有一些問題,雖然這些問題都有一定的解決辦法,但未達(dá)到喵喵想要的便捷和高效。
我們利用Stable diffusion生成圖片,圖片的風(fēng)格可以通過大模型或者Lycoris來控制,圖片的人物形象可以通過lora來控制,人物的動作可以通過controlnet的openpose,canny來控,圖片的質(zhì)量的可以通過放大算法來控制,但這些插件在應(yīng)用中依然有一些不足。
1.生成符合場景的圖片是最困難
在生成符合提示詞場景圖片方面,目前的一些插件和解決方法都有一些弊端,無法最大化提高生圖效率。
(1)以圖生圖方式:如果我們找的網(wǎng)圖質(zhì)量差,或者找的網(wǎng)圖和想要的場景不完全一樣,那么以圖生圖也很難得到自己想要的場景,重繪幅度越大,隨機(jī)性越大,即使通過局部重繪,也很難把圖片繪制得和想要的場景完全一致。
(2)利用controlnet插件的canny預(yù)處理器:canny預(yù)處理器可以識別所上傳圖片的輪廓和元素,可以較大程度地還原原圖的人物動作和場景。但是使用這個預(yù)處理器也有和圖生圖一樣的問題,如果我們上傳的原圖質(zhì)量不好,canny預(yù)處理器識別的噪點(diǎn)過多,那么生出來的圖片和想要的場景相差也很大。如果上傳是比較干凈的線稿,canny預(yù)處理器可以識別較為清晰的輪廓,但生出來的圖能不能和我們想象的一樣還得看模型的選擇、提示詞的編寫以及參數(shù)的調(diào)整。總之,想要生成自己想要的場景效率是比較慢的。

2.多人物的圖片生成是困難的
目前我們看到的很多大模型,lora模型基本都是單人物的模型,說明其在多人物生成方面是有困難的。雖然有一些插件和方法可以控制多人物的圖片生成,但是喵喵在實(shí)踐中還是覺得有隨機(jī)性,并且效率也不是很高。
(1)在控制多人物動作方面,可以使用controlnet插件的dw-openpose預(yù)處理器,處理方式也是找圖上傳,然后識別人物的動作,再結(jié)合我們的提示詞進(jìn)行生圖,甚至可以使用幾個controlnet疊加生成,提高了生成圖片和原圖的相似度,包括人物數(shù)量,動作,場景元素等。但是和圖生圖一樣,如果找到的網(wǎng)圖質(zhì)量不好,元素混亂,那么使用controlnet也很難得到一張適合的圖,要完全達(dá)到想要的圖片要求,還需要不斷調(diào)整模型、提示詞和參數(shù)。
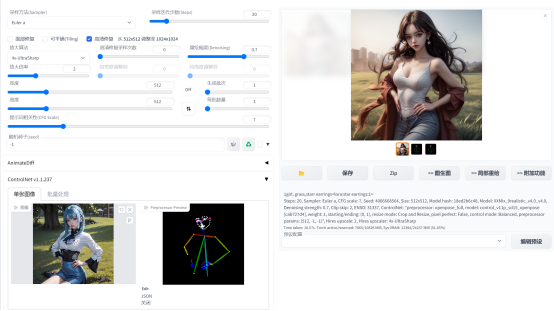
(3)在固定多人物形象方面,使用latend couple和Composable LoRA疊加使用兩個lora,分別渲染兩個人物,生成多人物的圖片,但是兩個lora有時候是會相互污染,即使調(diào)整參數(shù),也不能百分百達(dá)到自己想要的效果,多人物生成的隨機(jī)性比較高。有時候調(diào)用lora還會影響整體的圖片風(fēng)格,這可能是大模型和lora模型的兼容問題,也可能是lora的權(quán)重設(shè)置問題,雖然調(diào)整lora的權(quán)重可以緩解,但是有時候調(diào)整lora權(quán)重之后人物形象特征就不那么明顯了。因此,整體來說,多人物生圖的效率是很慢的,需要不斷地調(diào)整。
三、runway gen2和pika等視頻生成工具
文字生成視頻、圖片變成動態(tài)視頻也是近期的熱門工具,喵喵使用了runway gen2和pika,還有一個工具是animatediff,安裝了SD的插件,但是顯卡帶不動,爆顯存了,沒體驗(yàn)成功。整體的體驗(yàn)是pika的視頻更流暢,變形沒那么嚴(yán)重。
1.Animatediff
animatediff需要使用特定的大模型效果才更好,它是使用Stable diffusion一次性生成多張圖片,并把圖片組合在一起,使用一定的幀率組合成視頻。Animatediff只能生成幾秒的視頻。

2.runway gen2
runway gen2可以使用圖片生成視頻,也可以使用文字直接生成視頻,但是生成的視頻比較隨機(jī),有時候非常奇怪,要得到自己想要的視頻比較憑緣分。我們可以在discord上看到很多用戶的分享,有很多視頻丟失扭曲變形的。Konstantin的視頻

3.Pika
使用高質(zhì)量的圖片在pika上生成視頻效果相對比較好,pika目前在內(nèi)測,只能在他們的discord中進(jìn)行視頻生成。我們可以使用文字生成視頻,也可以使用圖片生成視頻,視頻時長3秒,且會損失畫質(zhì),如果我們提交的圖片畫質(zhì)本來就差,那么生出來的視頻的質(zhì)量會更差。因此,如果想要在pika上生成較好的視頻,注意上傳高清圖片。如果是使用文字生成,那么提示詞要寫清晰,這樣才能得到自己想要的場景視頻。
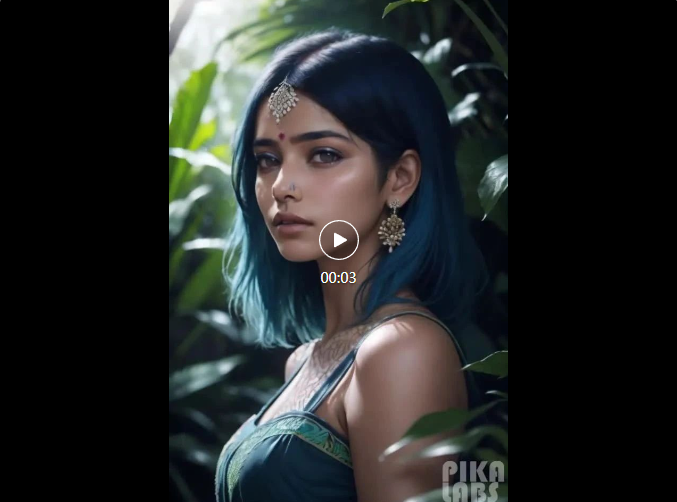
(來源:Google SEO 喵喵)
以上內(nèi)容屬作者個人觀點(diǎn),不代表雨果跨境立場!本文經(jīng)原作者授權(quán)轉(zhuǎn)載,轉(zhuǎn)載需經(jīng)原作者授權(quán)同意。?

 收錄于以下專欄
收錄于以下專欄












